
Dataset
In our experiments, we select the DB1404 dataset34, which is the only large-scale public Dongba script dataset. DB1404 contains 1,404 different characters with 2,546 writing styles, based on two authoritative Dongba dictionaries. It covers a comprehensive range of topics such as politics, history, economy, astronomy, geography, mythology, religion, philosophy, poetry, music, and dance. For our study, we use 10,000 images for training and 2,000 images for testing, each with a resolution of 256 × 256 pixels. To ensure comprehensive learning of the model under different masking rates, we strictly adhere to the mask configurations detailed in reference15. These configurations encompass irregular masking brush patterns—including random stroke masks, arbitrary block masks, and scattered point masks—with masking rates varying from 1% to 50%.
Experimental setup
The performance of the networks is quantitatively evaluated using PSNR48, SSIM47, FID37 and LPIPS49. All codes are implemented in Python using the PyTorch toolbox50. The training process begins with the ERCT module, optimized using the Adam optimizer with a learning rate of 6 × 10−4 for 1,000 steps. We then train the CMMA mechanism following34. Finally, the DBResNet and PDFC modules are trained together with the Adam optimizer, using learning rates of 1 × 10−3 for the generator and 1 × 10−4 for the discriminator, respectively. After 100k steps in the fine repair stage, we incrementally fine-tune them for just 50k steps and reduce the generator learning rate to 3 × 10−4.
That scheme led to the weight values λ1 = 10, λadv = 10, λfm = 100, λhrf = 30 and λms−ssim = 5. We use these hyperparameters to train all models, except those described in the loss ablation study. In all cases, the hyperparameter search is performed on a separate validation subset. All experiments in this study were conducted on the NVIDIA A800 (80G) GPU and implemented with the Python and PyTorch framework. The total number of parameters of the model is approximately 28.7M, including 6.2M for the ERCT module in the coarse inpainting stage, 4.5M for the CMMA module in the character matching stage, and 18.0M for the DBResNet+PDFC module in the fine inpainting stage. In terms of GPU memory requirements, the peak single-card memory usage during the training phase is about 22.3G, while the memory usage for a single 256 × 256 pixel image in the inference phase is only 3.8G, both falling within a reasonable range. As for the training time, the ERCT module in the coarse inpainting stage was trained for 1,000 steps taking about 1.2 hours; the CMMA module in the character matching stage was fine-tuned with a training time of approximately 2.5 hours; the DBResNet+PDFC module in the fine inpainting stage was trained for 150k steps consuming around 36 hours.
Superiority studies
We compare our proposed model with the following state-of-the-art models: Pix2Pix42, Edge Connect (EC)13, ZITS++17, LaMa45, Strdiffusion51, ControlNet52 and StDRB10. Among them, Pix2Pix and EC are classic inpainting models, ZITS++ is a transformer-based inpainting model, while LaMa and Strdiffusion are diffusion-based inpainting models. To make the comparison more convincing, the text inpainting model StDRB is additionally included. All competitors are compared on DB1404 with 256 × 256 resolution.
Table 1 shows the quantitative evaluation results on DB1404, using the irregular masks provided in the test set of15. The mask ratio from 1% to 50% represents the proportion of the image being masked. As the mask ratio increases, the amount of available information in the image decreases, leading to increased inpainting difficulty and a corresponding decline in various metrics. Notably, our model demonstrates superior performance across all evaluation metrics, outperforming other SOTA methods. This advantage is primarily attributed to its multi-stage inpainting strategy, which incrementally refines different aspects of the image, enabling finer control over both details and overall quality. As shown in Table 1, the Pix2Pix and EC models perform worse compared to others, while all models exhibit excellent performance within the mask ratio from 10% to 20%.
To intuitively illustrate the effectiveness of the proposed inpainting method, Fig. 7 presents the quantitative evaluation results for mask ratios ranging from 20% to 50%. The line charts clearly demonstrate the decline in performance metrics as the proportion of incompleteness increases. However, our method maintains optimal metrics and a relatively gentle slope across all ranges, indicating superior stability while sustaining excellent inpainting performance.

The mask rates are ranging from 20% to 50%.
Compared to the single-stage Pix2Pix model, the multi-stage inpainting strategy significantly enhances the inpainting quality by providing a richer set of detailed information. As shown in Table 1, although Pix2Pix generally exhibits the worst across all metrics, it surpasses EC in FID metric at mask ratios of 40–50%. This could be due to the EC emphasizing detailed information at the expense of overall image consistency, especially in case of extensive image damage. In contrast, our model excels in experimental results, particularly in metrics LPIPS and FID prioritizing human visual perception. Although EC employs a two-stage inpainting process, our model extracts and leverages more accurate priors and utilizes the Transformer architecture to better capture global information. This leads to significantly better performance across all metrics.
When compared to more advanced models such as ZITS++ and diffusion-based methods like LaMa and Strdiffusion, our model demonstrates unique strengths. The DBResNet module in our model is specifically designed for secondary feature extraction based on content priors. This design enhances its sensitivity and precision in restoring fine details. Although the advantage is less evident at lower mask ratios, Fig. 7 shows that as the mask ratio increases, the curve of our model exhibits a gentler slope. This indicates a slower performance decline compared to other models, further widening the gap as mask ratio increases.
Finally, compared to StDRB, a model specifically designed for text inpainting, our method shows superior performance, especially as the mask ratio increases. This is attributed to the incorporation of the Dongba dictionary into the model, which provides more accurate content priors for Dongba script. These priors are effectively utilized during inpainting, making their impact more significant as the mask ratio increases. Consequently, the advantage of our model becomes increasingly apparent at higher mask ratios.
Figure 8 presents qualitative inpainting results of various methods on the DB1404 dataset under irregular masks with mask rates, ranging from 10–20% to 40–50%. With increasing mask ratios, the inpainting quality of all models declines, particularly Pix2Pix, which exhibits the poorest image clarity and completeness. This is due to the single-stage repair process, which restricts its capacity to capture effective repair information. At lower mask rates, visible in the upper two rows of Fig. 8, most other models can essentially complete inpainting tasks. However, they fall short in fine detail inpainting compared to ours. For instance, the EC model produces noticeable artifacts, likely due to imprecise edge prediction during the inpainting process, resulting in unnatural outputs. At higher mask rates, depicted in the bottom two rows of Fig. 8, ours achieves more complete image inpainting. Even when the original image is masked to scattered points, our model guided by content priors, accurately reconstructs the strokes from these fragments. Although our inpainting lacks some strokes compared to the original, this is reasonable given that these strokes were entirely erased in the masked images.
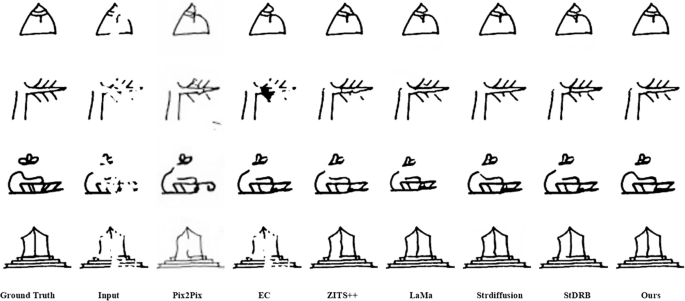
The mask rates of images range from 10-20% in the first row to 40–50% in the fourth row, with each row representing a 10% increase.
In summary, our model operates within a three-stage progressive repair framework. By integrating structure and content priors, it achieves superior metrics and robust performance in image inpainting, especially under high incompleteness.
Ablation studies
Next, we will respectively eliminate Multi-Head Convolutional Attention (MHCA) block, content prior(CP), and Dual-Branch ResNet (DBResNet) from our existing model to evaluate their individual effects on image inpainting, thereby confirming their effectiveness.
When inpainting the edge map, we employ MHCA in Edge Reconstruction Conv-Transformer (ERCT) to effectively combine convolution and Transformer models. We anticipate that the MHCA block will enhance the edge map quality by balancing local and global information, thereby improving the overall quality of the repaired image. The superior experimental results in Table 2, along with the more detailed edges and complete inpaintings illustrated in Fig. 9, confirm that the MHCA block meets our expectations. However, the model exhibits a slight deficiency in SSIM metric, as shown in Table 2. This could be attributed to the introduction of the MHCA block, which reallocates focus from global to local details. This shift may introduce noise and artifacts. Since SSIM is particularly sensitive to such disturbances, the metric may be slightly lower. Given that the core objective of Dongba script inpainting is to ensure structural authenticity and detailed completeness for semantic recognition, this minor SSIM trade-off is fully acceptable—MHCA significantly improves key metrics like PSNR, LPIPS, and FID, while enhancing stroke richness and visual consistency that are more critical for practical cultural heritage preservation. Nonetheless, the visual results in Fig. 9 show that our model enriches the details with the aid of MHCA, leading to more complete and visually consistent strokes. This enhancement in detail significantly boosts the overall image quality, as further validated by the experimental data in the table.
From top to bottom, the mask ratio increases.
Consequently, with the assistance of MHCA, the model focuses more on detailed information, resulting in clearer and more accurate edge maps. This enhancement in detail significantly improves inpainting quality, especially in the case of extensive degradation.
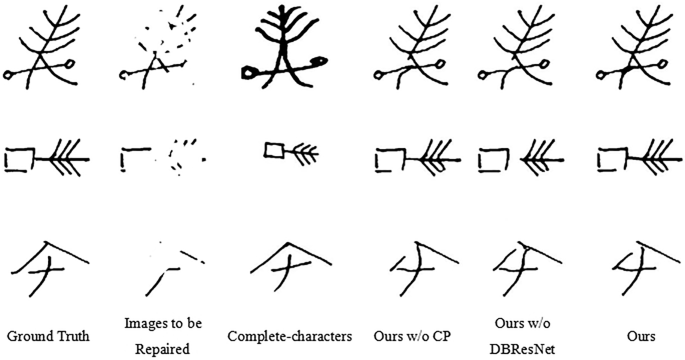
Next, we explore the impact of the content prior, namely complete-character, on model inpainting performance through comparative experiments. The structure prior is generated by ERCT, while the content prior is produced by CMMA. As illustrated in Table 3, our model exhibits superior overall performance, particularly in the inpainting of highly impaired. We speculate that this result is due to the guiding effect of the content prior. This guidance enables the model to repair incomplete images using strokes similar to those of the complete-characters, potentially leading to minor local deviations from the original. This could affect the scores of metrics like SSIM, which are sensitive to fine details. However, content priors offer an effective mechanism for filling in missing information, resulting in visually coherent and structurally plausible inpaintings, as shown in Fig. 10. This effectiveness is further evidenced by the significant optimization of the metrics in Fig. 11.

From top to bottom, the degree of mask rates increases.

The mask rates are ranging from 1% to 50%.
In summary, in the fine inpainting stage, complete-characters as content priors provide precise stroke directions and other fundamental details. This enables our model to exhibit strong adaptability and inpainting capability when handling images with significant information loss.
Influence of DBResNet on prior information utilization. As discussed before, content priors are vital for providing the model with detailed information such as strokes. To leverage this information, TsP introduces the Dual-Branch ResNet (DBResNet), designed to extract these features to enhance image inpainting quality. The experimental results in Table 4 and Fig. 11, along with the visual effects in Fig. 10 confirm that DBResNet meets our expectations. Notably, Fig. 11 illustrates an upward trend in model performance as content priors and DBResNet are incrementally integrated. This trend indicates that content priors can significantly enhance model performance and that DBResNet effectively leverages this information to further optimize the model.
Within DBResNet, the Content Feature Extraction (CFE) block and the Structure Feature Extraction (SFE) block independently extract the content and structure priors, respectively. These networks collaborate to filter and integrate the effective information from the priors into the subsequent inpainting process, resulting in more complete and visually coherent images. In high-damage image inpainting tasks, the correctness of stroke direction is crucial. With substantial detail loss, our focus shifts to maintaining the overall coherence and visual uniformity of the image. Designed specifically for high-damage inpainting tasks, our model is undoubtedly the optimal choice given its application scenario. Moreover, the visual results in Fig. 10 confirm that the model integrated with DBResNet produces more natural and credible results.
In summary, DBResNet effectively extracts prior features, providing the model with more effective guidance information. By effectively leveraging priors, it significantly enhances the inpainting performance.
Cao et al. 17 proposed a prior-guided image inpainting method, focusing on the overall inpainting performance aligned with the task. Consequently, we adopt the same loss weights as17. Given that our study employs black-and-white text images, contrasting with the color images in the reference, we place greater emphasis on visual quality. Therefore, we introduce the MS-SSIM loss function, which emphasizes overall visual impact without relying on color information. We conducted a series of weight adjustment experiments for this loss function, with detailed test results shown in Table 5.
Given the complementarity of the loss functions, we particularly focus on adjusting the weight of the feature match loss, λfm, in correspondence with the MS-SSIM loss weight, λms−ssim. This approach aims to evaluate the balance between the overall and detailed performance of the model under different weight configurations. Furthermore, to explore the balance among various loss functions, two additional sets of experiments are implemented with adjustments to all loss function weights. Particularly, we increase the initially lower weights λ1 and λadv.
Table 5 demonstrates that the weight configuration of the second group is optimal, yielding superior metrics. This outcome confirms that incorporating the MS-SSIM loss function enhances our inpainting capabilities. A detailed analysis reveals that when the MS-SSIM weight approaches the feature matching loss weight, the overall quality metrics, SSIM and LPIPS, decline. This indicates that these metrics have reached a threshold. Furthermore, reducing the variance among loss weights, as observed in the last two experimental groups, results in a significant performance drop. This suggests that maintaining an appropriate ratio between λfm and other loss weights is crucial for optimal model performance.